学術的な講演やプレゼンでは、統計調査についての説明が割とよく出てきたりします。で、その統計についての表記で、非常によく見受けられる誤字があります。
「この調査結果は、統計学的にユウイです」
「2つの母集団の間には、ユウイ差があります」
このような発言の「ユウイ」を「優位」としてしまう例です。正しくはもちろん「有意」(意味があること)です。
実はもう1つ、あまり意識されていない誤字があります。統計データの大きさを表す「エヌ」です。
A.「エヌは上場企業1,000社で、半分の500社から回答を得ました」
B.「20代の女性1,000人に対して調査を行いまして、回答者、エヌは300です」
皆さんなら、この2つの「エヌ」をどのように表記しますか?
もちろん「エヌ」はアルファベットの「エヌ」です。大文字か小文字かというのが問題です。
ちょっと考えてみてください。
正解は・・・
A.は大文字の「N」
B.の場合は小文字の「n」
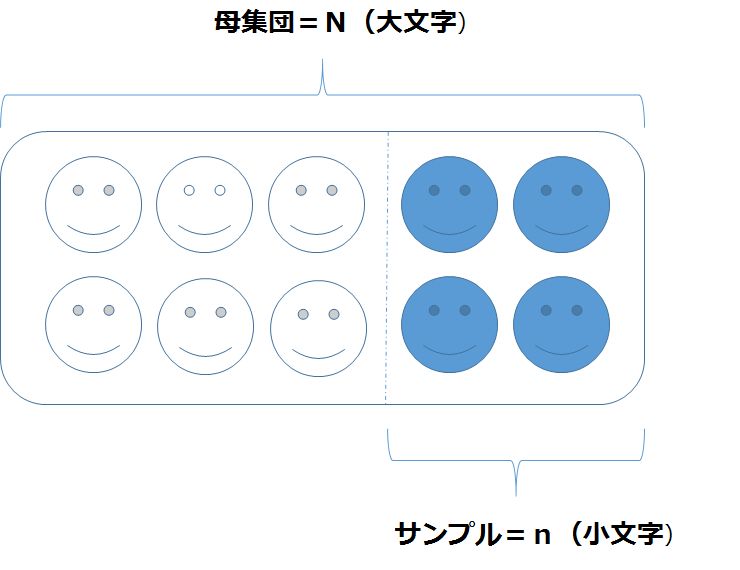
統計学の世界ではNとnは、厳密に使い分けられています。
母集団のサイズを表すときは大文字のN、その母集団から得たサンプル(標本)のサイズを表すときは小文字のnなんですね。
「1,000人を対象に調査をし、300人から回答を得た」という場合は、“N=1,000, n=300”と表します。
母集団を指しているのに「n」と表記したり、サンプルサイズなのに「N」としたりするのは、誤字になってしまいます。
●原稿の信頼性を決定づけるのは、細部の正確さ
「神はディテールに宿る」という言葉がありますが、原稿の信頼性を決定づけるのは、細部の正確さです。
どんなにすばらしい統計データを紹介しても、サンプルサイズが「N」と表記されているだけで、
「基本的な部分で間違ってるけど、この原稿、本当なの?」と疑われてしまうわけです。
逆にこのような細かいところまできっちり正確に表記されていると、「分かっているな」と原稿の信頼性もアップするはずですよ。